
OpenAI에서 개발한 CLIP(Contrastive Language-Image Pretraining) 모델은 이미지와 텍스트를 연결하는 다리와 같아요. 텍스트만으로도 이미지를 이해하고, 이미지만으로도 텍스트를 해석할 수 있도록 돕는 멋진 기술이죠! 혹시 이미지 분류나 검색, 콘텐츠 필터링 등에 관심이 있다면 CLIP 모델을 활용해보는 건 어떨까요? CLIP 모델을 제대로 이해하고 활용하려면 어떤 준비가 필요하고, 어떻게 사용해야 하는지 알아야겠죠? 이 글에서는 CLIP 모델의 기본 개념부터 직접 활용하는 방법까지 찬찬히 짚어볼게요.
CLIP 모델: 이미지와 텍스트의 만남

CLIP 모델은 텍스트와 이미지를 함께 이해하고 처리하는 멀티모달 AI 모델이에요. 마치 사람처럼 이미지를 보고 그 내용을 텍스트로 설명하거나, 텍스트를 보고 그 내용과 일치하는 이미지를 찾아낼 수 있답니다. OpenAI에서 개발한 CLIP은 방대한 양의 텍스트-이미지 쌍 데이터셋으로 사전 학습되었고, 다양한 작업에서 뛰어난 성능을 보여주고 있어요.
멀티모달 AI의 핵심, CLIP

CLIP 모델은 멀티모달 AI의 대표적인 예시 중 하나에요. 멀티모달 AI는 텍스트, 이미지, 음성, 비디오 등 여러 형태의 데이터를 동시에 처리하고 이해할 수 있는 인공지능을 말하는데요, CLIP은 텍스트와 이미지를 연결하는 데 특화되어 있어요. 텍스트와 이미지를 각각 인코딩하여 공통된 임베딩 공간에 매핑시켜, 이미지와 텍스트의 유사도를 측정하는 것이 핵심이죠.
제로샷 학습: 놀라운 CLIP의 능력
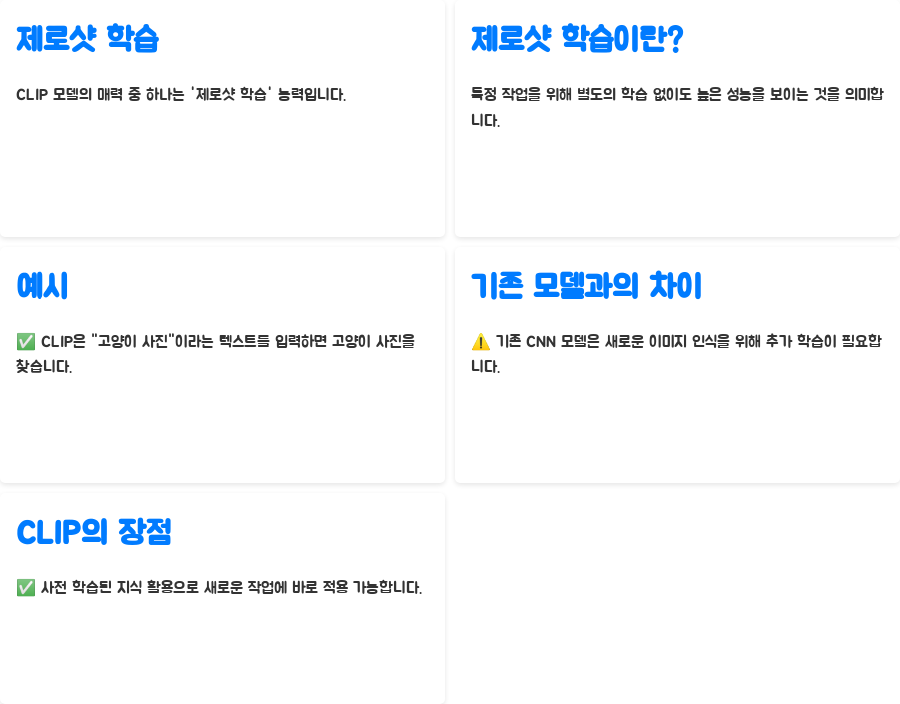
CLIP 모델의 또 다른 매력은 바로 '제로샷 학습' 능력이에요. 제로샷 학습은 특정 작업을 위해 별도의 학습 없이도 높은 성능을 보이는 것을 의미해요. 예를 들어, CLIP 모델은 '고양이' 사진을 학습한 적이 없더라도 "고양이 사진"이라는 텍스트를 입력하면 고양이 사진을 찾아낼 수 있답니다. 기존의 CNN 기반 이미지 인식 모델들은 새로운 종류의 이미지를 인식하려면 추가 학습이 필요했지만, CLIP은 사전 학습된 지식을 활용하여 새로운 작업에도 곧바로 적용할 수 있다는 장점이 있어요.
CLIP 모델의 활용: 다양한 가능성

CLIP 모델은 이미지 인식, 이미지 검색, 이미지 생성, 콘텐츠 필터링 등 다양한 분야에 활용될 수 있어요. 예를 들어, 쇼핑몰에서 원하는 옷을 찾을 때 "파란색 셔츠"라고 검색하면 CLIP 모델이 이 텍스트를 이해하고 해당하는 이미지를 보여주는 것이죠. 혹은, 유튜브에서 "강아지가 나오는 영상"을 찾을 때 CLIP 모델이 영상의 내용을 분석하여 강아지가 나오는 장면을 찾아주는 것도 가능해요.
CLIP 모델 직접 활용하기: 간단한 코드로 시작

CLIP 모델을 직접 활용해보고 싶다면, 파이썬과 패키지를 사용하면 돼요. Hugging Face에서 제공하는 패키지는 CLIP 모델을 쉽게 사용할 수 있도록 도와주는 아주 유용한 도구랍니다.
1단계: 환경 설정

먼저, Python 환경에서 패키지를 설치해야 해요. 아래 명령어를 실행하면 쉽게 설치할 수 있어요.
pip install transformers2단계: 모델 로드
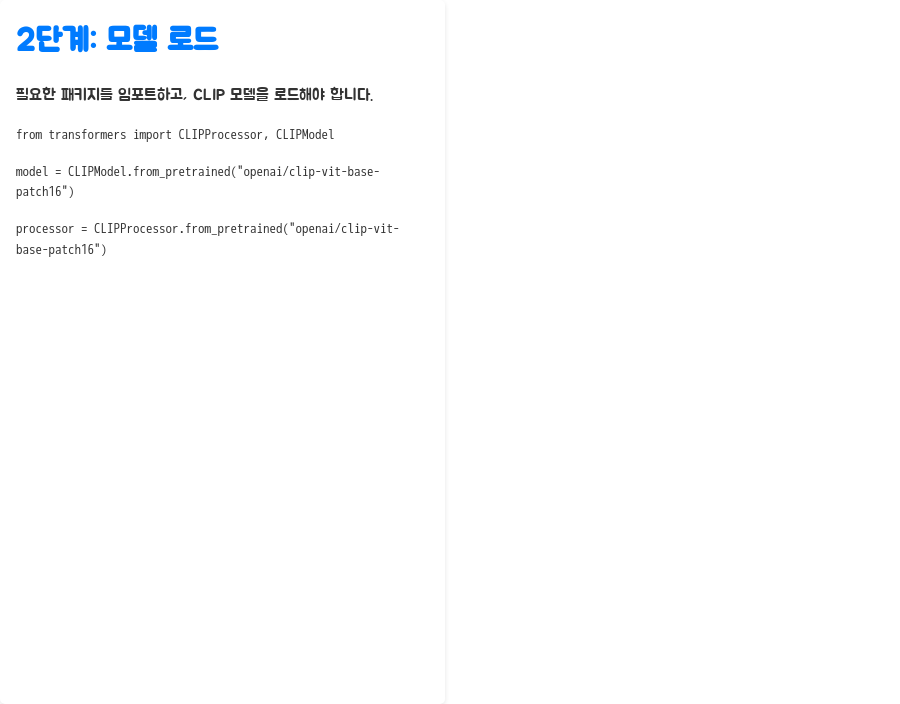
필요한 패키지를 임포트하고, CLIP 모델을 로드해 줘야겠죠? 아래 코드를 참고해보세요.
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")3단계: 이미지 및 텍스트 준비

이제 모델에 입력할 이미지와 텍스트를 준비해야 해요. 웹 URL 또는 로컬 파일에서 이미지를 불러오고, 원하는 텍스트 설명을 작성하면 돼요.
from PIL import Image
import requests
url = "이미지_URL"
image = Image.open(requests.get(url, stream=True).raw)
text = "설명할 텍스트"4단계: 모델 실행

준비된 이미지와 텍스트를 모델에 입력하고 결과를 확인해 보세요.
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)5단계: 결과 분석

모델의 출력을 분석하여 이미지와 텍스트 간의 유사도를 확인하거나, 다른 작업에 활용할 수 있어요. 예를 들어, 이미지 분류 작업을 한다면, 모델의 출력값을 기반으로 이미지에 가장 적합한 텍스트 레이블을 예측할 수 있겠죠?
CLIP 모델의 한계와 미래

CLIP 모델은 뛰어난 성능을 보이지만, 여전히 몇 가지 한계점을 가지고 있어요. 예를 들어, 복잡하거나 모호한 이미지를 정확하게 이해하는 데 어려움을 겪을 수 있고, 텍스트의 뉘앙스나 감정을 완벽하게 파악하지 못하는 경우도 있답니다.
하지만 CLIP 모델은 계속해서 발전하고 있으며, 앞으로 더욱 다양한 분야에서 활용될 것으로 예상돼요. 멀티모달 AI 기술의 발전과 함께 CLIP 모델은 이미지와 텍스트를 연결하는 핵심 기술로 자리매김할 가능성이 높아요.
CLIP 모델 활용을 위한 팁

1. 명확하고 구체적인 텍스트 입력:
CLIP 모델이 이미지를 정확하게 이해하도록 돕기 위해서는 명확하고 구체적인 텍스트를 입력하는 것이 중요해요. "강아지 사진"보다는 "귀여운 강아지가 뛰어노는 사진"과 같이 구체적인 텍스트를 입력하면 더욱 정확한 결과를 얻을 수 있답니다.
2. 다양한 텍스트 쿼리 시도:
만약 원하는 결과를 얻지 못했다면, 다른 텍스트 쿼리를 시도해보는 것이 좋아요. 같은 의미를 표현하더라도 텍스트 표현 방식에 따라 CLIP 모델의 반응이 달라질 수 있으니까요.
3. 이미지 전처리 활용:
이미지의 크기나 품질에 따라 CLIP 모델의 성능이 달라질 수 있어요. 이미지 전처리 기법을 활용하여 이미지의 크기를 조정하거나 품질을 개선하면 더 나은 결과를 얻을 수 있답니다.
4. CLIP 모델의 한계 인지:
CLIP 모델은 모든 이미지를 완벽하게 이해할 수는 없어요. 특히, 복잡하거나 모호한 이미지의 경우 정확도가 떨어질 수 있다는 점을 인지하고, 결과를 해석할 때 주의해야 한답니다.
QnA: 자주 묻는 질문
Q1. CLIP 모델은 어떤 분야에서 활용될 수 있나요?

A1. CLIP 모델은 이미지 인식, 이미지 검색, 이미지 생성, 콘텐츠 필터링 등 다양한 분야에서 활용될 수 있어요. 특히, 이미지와 텍스트를 연결하는 작업에 유용하게 사용될 수 있답니다.
Q2. CLIP 모델은 어떻게 학습되나요?

A2. CLIP 모델은 방대한 양의 텍스트-이미지 쌍 데이터셋으로 사전 학습돼요. 이미지와 텍스트를 각각 인코딩하여 공통된 임베딩 공간에 매핑시켜, 이미지와 텍스트의 유사도를 측정하는 방식으로 학습되죠.
Q3. CLIP 모델의 장점은 무엇인가요?

A3. CLIP 모델의 가장 큰 장점은 제로샷 학습 능력이에요. 별도의 학습 없이도 새로운 작업에 적용할 수 있다는 점이 큰 장점이죠. 또한, 텍스트와 이미지를 연결하여 다양한 작업을 수행할 수 있다는 점도 매력적이에요.
마무리

CLIP 모델은 이미지와 텍스트를 연결하는 멋진 기술이며, 앞으로 더욱 다양한 분야에서 활용될 가능성이 높아요. 이 글을 통해 CLIP 모델을 조금 더 잘 이해하고, 직접 활용해 보는 데 도움이 되었기를 바라요!
키워드
CLIP, 멀티모달, AI, 인공지능, 이미지인식, 텍스트처리, 이미지검색, 제로샷학습, 컴퓨터비전, 자연어처리, 머신러닝, 딥러닝, 오픈AI, HuggingFace, transformers, Python, 코드, 튜토리얼, 데이터과학, 인공지능개발, 멀티모달AI, 비전트랜스포머, 트랜스포머, 임베딩, 잠재공간, VAE, 멀티모달학습, ImageBind, 메타AI, 사전학습, 코사인유사도, crossentropy, ResNet, VisionTransformer, zero-shotlearning, ImageNet, Food101, SUN397



