
텍스트 임베딩이 뭔지, 궁금했던 적 있으세요? 챗GPT나 뭐 이런 AI들이 어떻게 우리 말을 알아듣고, 막 똑똑한 척 대답하는지 신기하지 않으세요? 사실, 그 똑똑함 뒤에는 텍스트를 숫자로 바꾸는 엄청난 마법이 숨겨져 있어요.
AI 모델들은 우리가 하는 말을 직접 이해하는 게 아니라, 그 말을 숫자로 바꿔서 분석하고, 또 숫자를 다시 우리가 이해할 수 있는 말로 바꿔서 답하는 거랍니다.
이 숫자로 바꾸는 과정, 바로 텍스트 임베딩이라는 거예요.
어려운 말 같지만, 쉽게 생각하면 돼요. 마치 우리가 외국어를 한국어로 번역하듯이, AI 모델은 텍스트를 컴퓨터가 이해하는 숫자 언어로 바꾸는 거죠. 그리고 그 과정에서 텍스트가 가진 의미, 문맥, 그리고 단어들 사이의 관계까지 숫자에 담아내는 거예요.
언어 모델과 임베딩 모델: 텍스트를 숫자로 표현하는 방법
언어 모델은 말 그대로 인간 언어를 이해하고 처리하는 모델이에요. 특히, 주어진 문장이나 단어를 보고 다음에 어떤 단어가 나올지 예측하는 데 능력을 발휘하죠.
반면에 임베딩 모델은 텍스트를 숫자 벡터로 변환하는 모델이라고 생각하면 돼요. 즉, "사랑"이라는 단어를 [0.123, 0.456, 0.789...] 와 같은 숫자들의 집합으로 바꾸는 거죠. 이렇게 텍스트를 숫자 벡터로 바꾸면 컴퓨터가 텍스트를 숫자로 처리할 수 있게 되는 거고, 그 결과 텍스트의 의미를 수학적으로 계산하고 비교할 수 있게 되는 거예요.
예를 들어, 챗봇 개발, 문서 요약, 기계 번역, 감정 분석 등에 활용될 수 있죠.
임베딩 과정: 텍스트를 숫자 벡터로 변환하기
언어 모델을 임베딩 모델로 활용하는 과정은 몇 가지 단계를 거쳐요.
- 단어 임베딩 생성:
- 먼저, 텍스트를 구성하는 각 단어를 고정된 차원의 벡터로 변환하는 작업을 수행해요. 이때, Word2Vec, GloVe, FastText와 같은 다양한 임베딩 알고리즘을 사용할 수 있어요. 이 알고리즘들은 주변 단어들을 참고하여 단어의 의미를 벡터로 표현하도록 학습되죠. 예를 들어, "사랑"이라는 단어가 자주 "행복", "기쁨"과 같은 단어들과 함께 나타난다면, "사랑"의 벡터는 "행복"과 "기쁨"의 벡터와 비슷한 값을 갖게 될 거예요.
- 포지션 임베딩 추가:
- 단어의 순서 정보를 벡터에 추가하는 작업이에요. 특히, Transformer 기반 모델에서 중요한 역할을 하는데, 문장 내에서 단어의 위치 정보를 반영하여 문맥을 더 정확하게 파악할 수 있도록 돕죠.
- 문장 임베딩 생성:
- 여러 단어의 임베딩을 결합하여 문장 전체를 나타내는 벡터를 생성해요. 이 과정에서는 단어 벡터들의 평균 또는 합산 등의 방법을 사용할 수 있고, 문장의 의미를 하나의 벡터로 표현하게 되죠.
언어 모델을 임베딩 모델로 활용하기: 다양한 NLP 태스크 적용
임베딩 모델은 다양한 자연어 처리 태스크에 활용될 수 있어요.
1. 문서 분류: 텍스트의 주제를 분류하기
텍스트의 주제를 분류하는 데 사용될 수 있어요. 예를 들어, 뉴스 기사를 스포츠, 정치, 경제 등의 카테고리로 분류하는 작업에 활용될 수 있죠. 텍스트를 벡터로 변환한 후, 머신러닝 분류 알고리즘을 사용하여 각 문서가 어떤 카테고리에 속하는지 예측할 수 있어요.
2. 감정 분석: 텍스트의 감정을 판단하기
텍스트의 감정을 판단하는 데 유용해요. 긍정적, 부정적, 중립적 등의 감정을 분류하거나, 감정의 강도를 측정하는 데 활용될 수 있죠. 예를 들어, 상품 리뷰를 분석하여 고객의 만족도를 파악하거나, 소셜 미디어 게시글의 감정을 분석하여 여론을 파악하는 데 사용될 수 있어요.
3. 질의응답 시스템: 사용자 질문에 대한 답변 찾기
사용자의 질문에 대한 답변을 찾는 데 도움을 줄 수 있어요. 사용자 질문과 문서를 벡터로 변환한 후, 두 벡터 간의 유사도를 계산하여 질문과 관련된 문서를 찾을 수 있죠. 예를 들어, 검색 엔진에서 사용자 질문에 가장 적합한 문서를 검색하거나, 챗봇에서 사용자 질문에 대한 답변을 찾는 데 활용될 수 있어요.
임베딩 모델 구현: 파이썬으로 직접 만들어보기
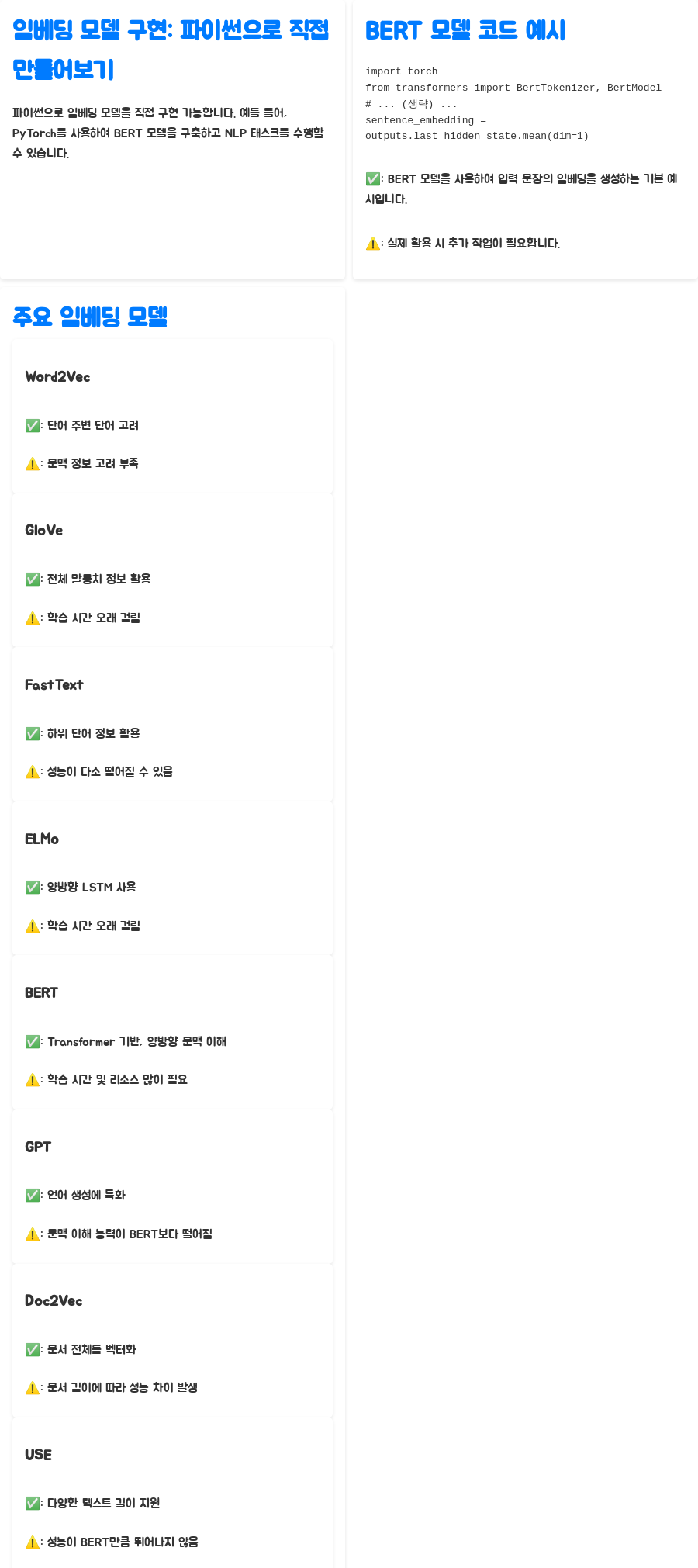
파이썬과 같은 프로그래밍 언어를 사용하여 임베딩 모델을 구현할 수 있어요. 예를 들어, PyTorch 라이브러리를 이용한 BERT 모델을 구축하여 여러 NLP 태스크를 동시에 수행하도록 설계할 수 있죠.

아래는 BERT 모델을 사용하여 입력 문장의 임베딩을 생성하는 간단한 코드 예시에요.
import torch
from transformers import BertTokenizer, BertModel
# BERT 모델과 토크나이저 초기화
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 입력 문장
sentence = "안녕하세요, 오늘 날씨가 어때요?"
# 토큰화 및 인덱스 변환
inputs = tokenizer(sentence, return_tensors='pt')
# 임베딩 생성
with torch.no_grad():
outputs = model(**inputs)
# 문장 임베딩
sentence_embedding = outputs.last_hidden_state.mean(dim=1)코드는 BERT 모델을 사용하여 입력 문장의 임베딩을 생성하는 기본적인 예시에요. 물론, 실제로 임베딩 모델을 구축하고 활용하려면 더 많은 작업이 필요하지만, 이 코드를 통해 기본적인 원리를 이해하는 데 도움이 되길 바라요.
| Word2Vec | 단어의 주변 단어를 고려 | 단어 간 유사성 파악 용이 | 문맥 정보 고려 부족 |
| GloVe | 전체 말뭉치 정보 활용 | Word2Vec보다 성능 우수 | 학습 시간 오래 걸림 |
| FastText | 하위 단어 정보 활용 | OOV 문제 해결 | 성능이 다른 모델에 비해 다소 떨어질 수 있음 |
| ELMo | 양방향 LSTM 사용 | 문맥 정보 반영 | 학습 시간 오래 걸림 |
| BERT | Transformer 기반, 양방향 문맥 이해 | 뛰어난 성능 | 학습 시간 및 리소스 많이 필요 |
| GPT | 언어 생성에 특화 | 일관성 있는 텍스트 생성 | 문맥 이해 능력이 BERT보다 떨어짐 |
| Doc2Vec | 문서 전체를 벡터화 | 문서 간 유사성 비교 용이 | 문서 길이에 따라 성능 차이 발생 |
| USE | 다양한 텍스트 길이 지원 | 의미적 유사성 고려 | 성능이 BERT만큼 뛰어나지 않음 |
모델 특징 장점 단점
마무리: 언어 모델과 임베딩 모델, 그리고 텍스트의 마법
언어 모델을 임베딩 모델로 활용하는 것은 텍스트 데이터를 컴퓨터가 이해할 수 있도록 변환하고, 다양한 NLP 태스크를 수행하는 데 필수적인 과정이에요.
이 과정을 통해 컴퓨터는 텍스트의 의미를 파악하고, 우리가 원하는 대로 텍스트 데이터를 처리할 수 있게 되는 거죠. 앞으로도 딥러닝 기술의 발전과 함께 더욱 다양하고 정교한 언어 모델과 임베딩 모델이 개발될 것으로 예상되고, 이를 통해 인공지능은 인간의 언어를 더욱 잘 이해하고, 더욱 유용한 서비스를 제공할 수 있을 거예요.
자주 묻는 질문 (FAQ)
Q1. 텍스트 임베딩이 왜 중요한가요?
A1. 텍스트 임베딩은 컴퓨터가 텍스트 데이터를 이해하고 처리할 수 있도록 텍스트를 숫자 벡터로 변환하는 기술이에요. 이를 통해 컴퓨터는 텍스트의 의미를 파악하고, 다양한 NLP 태스크를 수행할 수 있게 되죠.
Q2. 언어 모델과 임베딩 모델의 차이점은 무엇인가요?
A2. 언어 모델은 텍스트 데이터를 학습하여 다음에 올 단어를 예측하는 모델이고, 임베딩 모델은 텍스트를 숫자 벡터로 변환하는 모델이에요. 언어 모델은 임베딩 모델을 활용하여 텍스트를 이해하고 처리할 수 있죠.
Q3. 어떤 텍스트 임베딩 모델을 선택해야 할까요?
A3. 처리하려는 텍스트 데이터의 특징과 목표하는 NLP 태스크에 따라 적절한 모델을 선택해야 해요. 예를 들어, 문맥 정보를 중요하게 고려해야 한다면 BERT나 ELMo를 선택하는 것이 좋고, 단어 간 유사성을 파악하는 데 중점을 둔다면 Word2Vec을 선택하는 것이 좋을 수 있어요.
키워드 언어모델,임베딩모델,텍스트임베딩,NLP,자연어처리,Word2Vec,GloVe,FastText,ELMo,BERT,GPT,Doc2Vec,USE,딥러닝,AI,인공지능,챗봇,기계번역,문서분류,감정분석,질의응답,파이썬,PyTorch,머신러닝,데이터과학,텍스트데이터,한국어처리,자연어이해,AI활용,AI기술,챗봇개발,텍스트분석



